It is when you’re a cloud hosting platform and you have 1000’s of photos uploaded daily. That 44k saving scales massively when talking about cloud hosting platforms. The jpeg xl format license is more open than webp which is controlled by google.
The new format also enables more features than just file size, a quick google shows it supports animation, 360 photos, and image bursts (as well as more technical specifics that allow for better share ability without needing to have an accompanying json file or dropping to RAW).
This is more important because it means websites can embed photos and the web engine whether it be chromium, Firefox, or safari can handle it natively without needing JavaScript or some other intermediary.
What about png? It’s just another competing standard. At the end of the day it doesn’t really matter, but by not having competing standards we end up having one company controlling it. So since at the very least it gives a decent file size saving it’s good enough for me.
Even better, this must be fantastic when you’re training AI models with millions of images. The compression level AND performance should be a game changer.
Hmm, I haven’t delved into image training in a couple years so I’m assuming they still downscale images anyway, so I’m not sure how much the format helps? Do you know if better compression helps at lower resolution? I could see it helping but I could also seeing it be marginal gains and depending on processing time it might not be worth it to convert whole image sets to jpeg xl. And for performance does jpeg xl require less power/time to decode than other formats? Maybe for new image sets going forward it will be the standard.
Oh, I’ve just been toying around with Stable Diffusion and some general ML tidbits. I was just thinking from a practical point of view. From what I read, it sounds like the files are smaller at the same quality, require the same or less processor load (maybe), are tuned for parallel I/O, can be encoded and decoded faster (and there being less difference in performance between the two), and supports progressive loading. I’m kinda waiting for the catch, but haven’t seen any major downsides, besides less optimal performance for very low resolution images.
I don’t know how they ingest the image data, but I would assume they’d be constantly building sets, rather than keeping lots of subsets, if just for the space savings of de-duplication.
(I kinda ramble below, but you’ll get the idea.)
Mixing and matching the speed/efficiency and storage improvement could mean a whole bunch of improvements. I/O is always an annoyance in any large set analysis. With JPEG XL, there’s less storage needed (duh), more images in RAM at once, faster transfer to and from disc, fewer cycles wasted on waiting for I/O in general, the ability to store more intermediate datasets and more descriptive models, easier to archive the raw photo sets (which might be a big deal with all the legal issues popping up), etc. You want to cram a lot of data into memory, since the GPU will be performing lots of operations in parallel. Accessing the I/O bus must be one of the larger time sinks and CPU load becomes a concern just for moving data around.
I also wonder if the support for progressive loading might be useful for more efficient, low resolution variants of high resolution models. Just store one set of high res images and load them in progressive steps to make smaller data sets. Like, say you have a bunch of 8k images, but you only want to make a website banner based on the model from those 8k res images. I wonder if it’s possible to use the the progressive loading support to halt reading in the images at 1k. Lower resolution = less model data = smaller datasets to store or transfer. Basically skipping the downsampling.
Any time I see a big feature jump, like better file size, I assume the trade off in another feature negates at least half the benefit. It’s pretty rare, from what I’ve seen, to have improvements on all fronts.


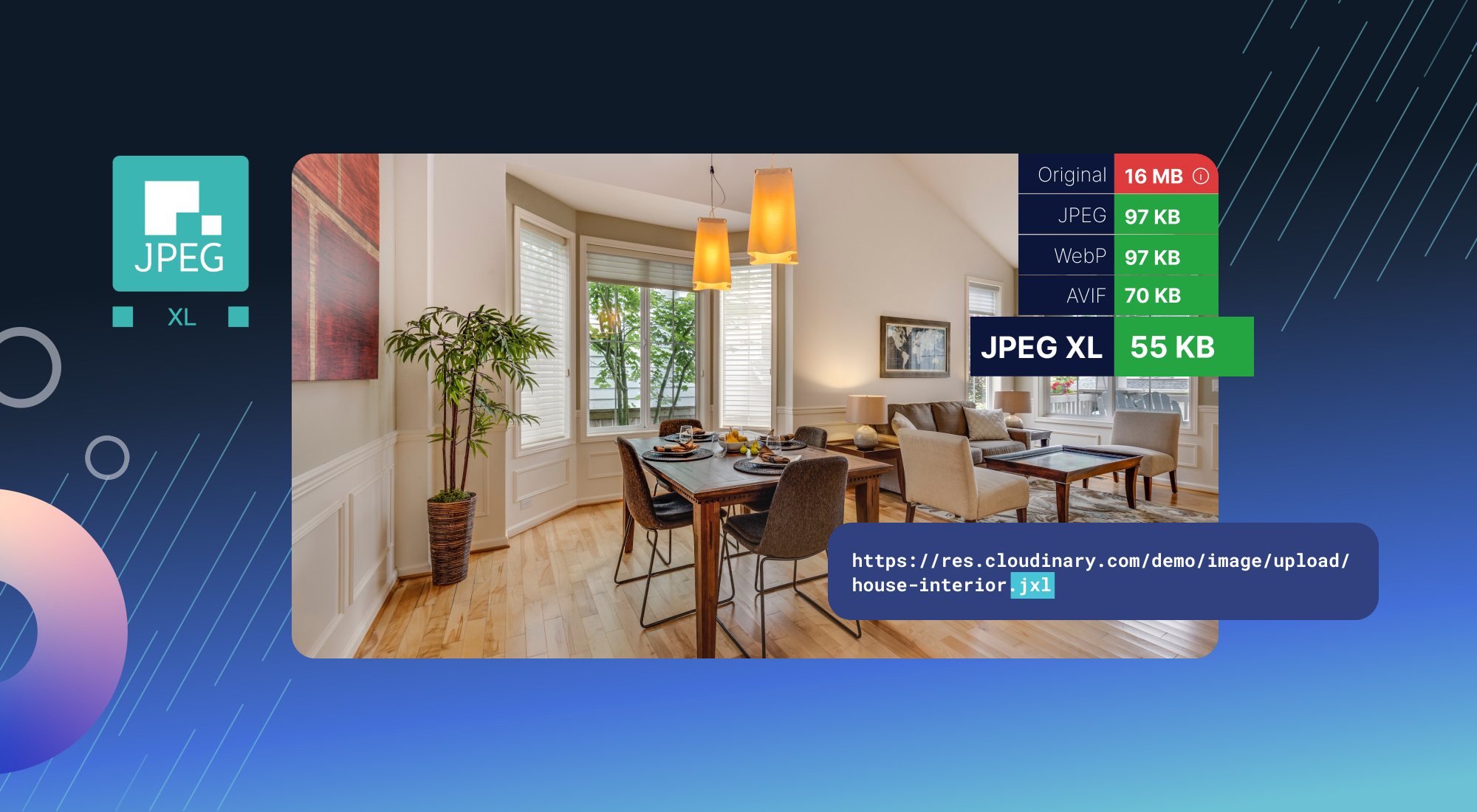
It is when you’re a cloud hosting platform and you have 1000’s of photos uploaded daily. That 44k saving scales massively when talking about cloud hosting platforms. The jpeg xl format license is more open than webp which is controlled by google.
The new format also enables more features than just file size, a quick google shows it supports animation, 360 photos, and image bursts (as well as more technical specifics that allow for better share ability without needing to have an accompanying json file or dropping to RAW).
This is more important because it means websites can embed photos and the web engine whether it be chromium, Firefox, or safari can handle it natively without needing JavaScript or some other intermediary.
What about png? It’s just another competing standard. At the end of the day it doesn’t really matter, but by not having competing standards we end up having one company controlling it. So since at the very least it gives a decent file size saving it’s good enough for me.
Even better, this must be fantastic when you’re training AI models with millions of images. The compression level AND performance should be a game changer.
Hmm, I haven’t delved into image training in a couple years so I’m assuming they still downscale images anyway, so I’m not sure how much the format helps? Do you know if better compression helps at lower resolution? I could see it helping but I could also seeing it be marginal gains and depending on processing time it might not be worth it to convert whole image sets to jpeg xl. And for performance does jpeg xl require less power/time to decode than other formats? Maybe for new image sets going forward it will be the standard.
Oh, I’ve just been toying around with Stable Diffusion and some general ML tidbits. I was just thinking from a practical point of view. From what I read, it sounds like the files are smaller at the same quality, require the same or less processor load (maybe), are tuned for parallel I/O, can be encoded and decoded faster (and there being less difference in performance between the two), and supports progressive loading. I’m kinda waiting for the catch, but haven’t seen any major downsides, besides less optimal performance for very low resolution images.
I don’t know how they ingest the image data, but I would assume they’d be constantly building sets, rather than keeping lots of subsets, if just for the space savings of de-duplication.
(I kinda ramble below, but you’ll get the idea.)
Mixing and matching the speed/efficiency and storage improvement could mean a whole bunch of improvements. I/O is always an annoyance in any large set analysis. With JPEG XL, there’s less storage needed (duh), more images in RAM at once, faster transfer to and from disc, fewer cycles wasted on waiting for I/O in general, the ability to store more intermediate datasets and more descriptive models, easier to archive the raw photo sets (which might be a big deal with all the legal issues popping up), etc. You want to cram a lot of data into memory, since the GPU will be performing lots of operations in parallel. Accessing the I/O bus must be one of the larger time sinks and CPU load becomes a concern just for moving data around.
I also wonder if the support for progressive loading might be useful for more efficient, low resolution variants of high resolution models. Just store one set of high res images and load them in progressive steps to make smaller data sets. Like, say you have a bunch of 8k images, but you only want to make a website banner based on the model from those 8k res images. I wonder if it’s possible to use the the progressive loading support to halt reading in the images at 1k. Lower resolution = less model data = smaller datasets to store or transfer. Basically skipping the downsampling.
Any time I see a big feature jump, like better file size, I assume the trade off in another feature negates at least half the benefit. It’s pretty rare, from what I’ve seen, to have improvements on all fronts.
deleted by creator